突破AI和机器理解的界限牛津CS博士143页毕业论文学习重建和分割3D物体
突破AI和机器理解的界限牛津CS博士143页毕业论文学习重建和分割3D物体。让机器拥有像人类一样感知 3D 物体和环境的能力,是人工智能领域的一项重要课题。牛津大学计算机科学系博士生 Bo Yang 在其毕业论文中详细解读了如何重建和分割 3D 物体,进而赋予机器感知 3D 环境的能力,突破了人工智能和机器理解的界限。
赋予机器像人类一样感知三维真实世界的能力,这是人工智能领域的一个根本且长期存在的主题。考虑到视觉输入具有不同类型,如二维或三维传感器获取的图像或点云,该领域研究中一个重要的目标是理解三维环境的几何结构和语义。
传统方法通常利用手工构建的特征来估计物体或场景的形状和语义。但是,这些方法难以泛化至新物体和新场景,也很难克服视觉遮挡的关键问题。
今年九月毕业于牛津大学计算机科学系的博士生 Bo Yang 在其毕业论文《Learning to Reconstruct and Segment 3D Objects》中对这一主题展开了研究。与传统方法不同,作者通过在大规模真实世界的三维数据上训练的深度神经网络来学习通用和鲁棒表示,进而理解场景以及场景中的物体。
总体而言,本文开发了一系列新型数据驱动算法,以实现机器感知到真实世界三维环境的目的。作者表示:「本文可以说是突破了人工智能和机器理解的界限。」
这篇博士论文有 143 页,共六章。机器之心对该论文的核心内容进行了简要介绍,感兴趣的读者可以阅读论文原文。

作者在第 2 章首先回顾了以往 3D 物体重建和分割方面的研究工作,包括单视图和多视图 3D 物体重建、3D 点云分割、对抗生成网络(GAN)、注意力机制以及集合上的深度学习。此外,本章最后还介绍了在单视图 / 多视图 3D 重建和 3D 点云分割方面,该研究相较于 SOTA 方法的新颖之处。
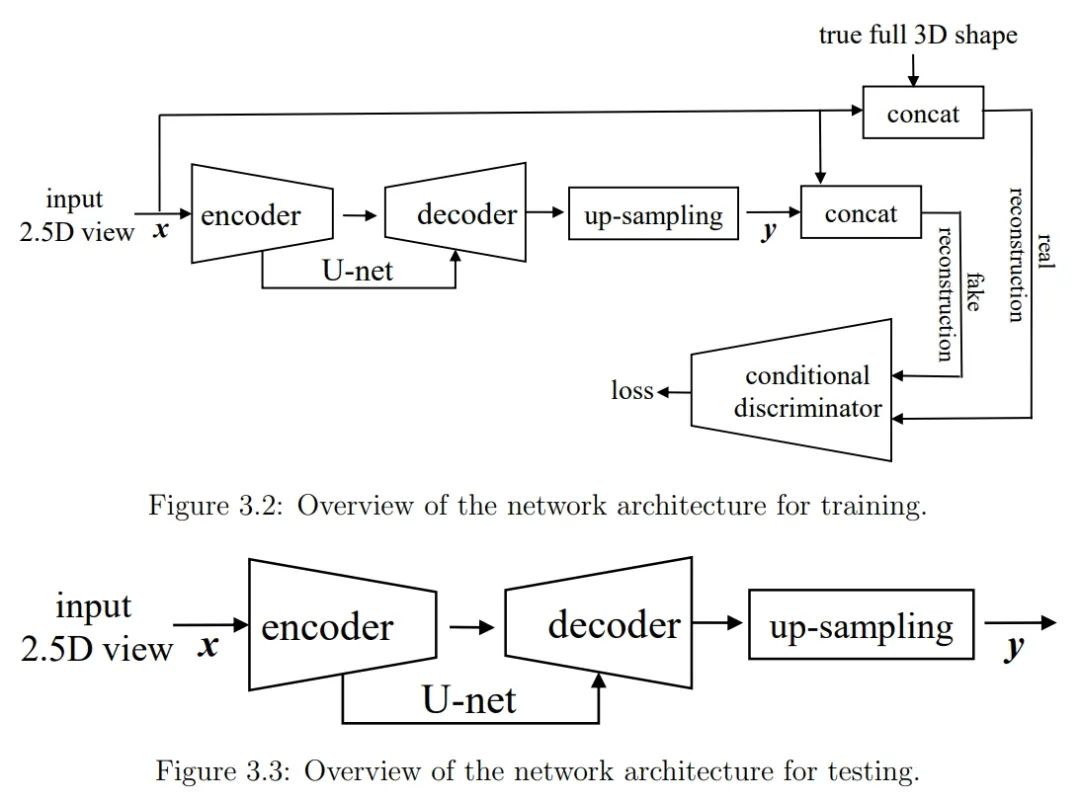
在第 3 章,作者提出以一种基于 GAN 的深度神经架构来从单一的深度视图学习物体的密集 3D 形状。作者将这种简单但有效的模型称为 3D-RecGAN++,它将残差连接(skip-connected)的 3D 编码器 - 解码器和对抗学习结合,以生成单一 2.5D 视图条件下的完整细粒度 3D 结构。该模型网络架构的训练和测试流程如下图所示:
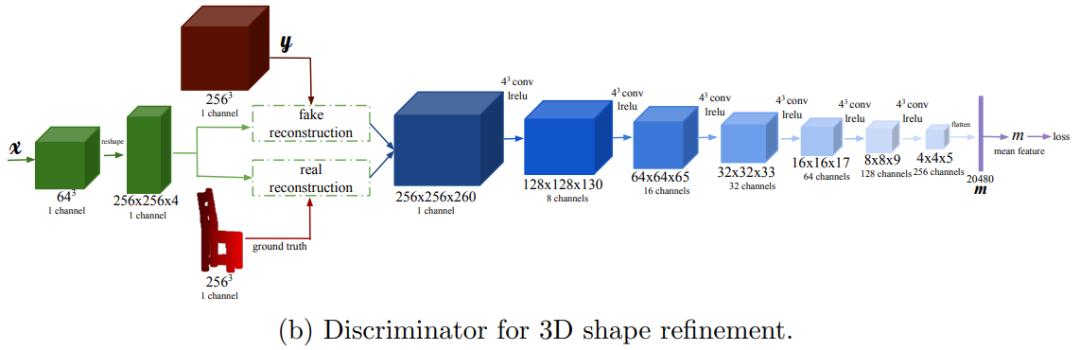
接着,作者利用条件对抗训练来细化编码器 - 解码器估计的 3D 形状,其中用于 3D 形状细化的判别器结构示意图如下:
最后,作者将提出的 3D-RecGAN++ 与 SOTA 方法做了对比,并进行了控制变量研究。在合成和真实数据集上的大量实验结果表明,该模型性能良好。
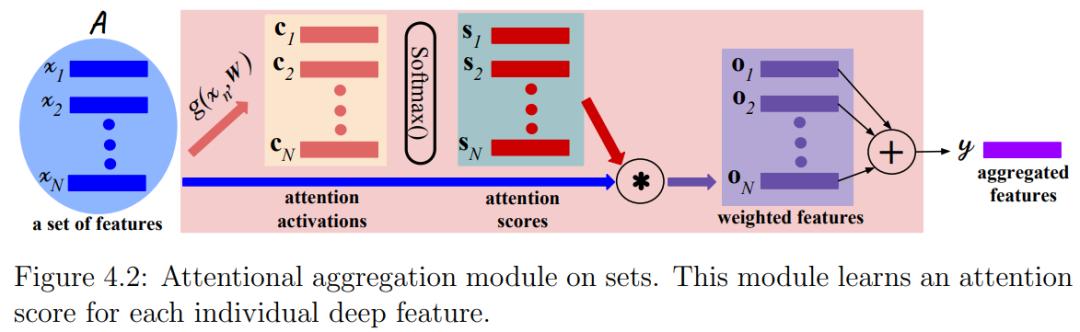
在第 4 章,作者提出以一种新的基于注意力机制的神经模块来从多视图中推理出更好的 3D 物体形状。这种简单但高效的注意力聚合模块被称为 AttSets推荐阅读:课题写作,其结构如下图所示。与现有方法相比,这种方法可以学习从不同图像中聚合有用信息。
此外,研究者还引入了两阶段训练算法,以确保在给出一定数量输入图像的情况下,预估的 3D 形状具有鲁棒性。研究者在多个数据集上进行了实验,证明该方法能够精确地恢复物体的 3D 形状。
在第五章中,研究者提出了一个新的框架来识别大规模 3D 场景中的所有单个 3D 物体。与现有的研究相比,该研究的框架能够直接并且同时进行检测、分割和识别所有的目标实例,而无需任何繁琐的前 / 后处理步骤。研究者在多个大型实际数据集上展现了该方法相对于基线的性能提升。
本文作者 Bo Yang 现为香港理工大学计算机系助理教授。他本科和硕士分别毕业于北京邮电大学和香港大学,然后进入牛津大学计算机科学系攻读博士学位,其导师为 Niki Trigoni 和 Andrew Markham 教授。
Bo Yang 作为一作以及合著的论文曾被《计算机视觉国际期刊》(IJCV)以及 NeurIPS 和 CVPR 等学术会议接收,谷歌学术主页上显示他共著有 22 篇论文,被引用数超过 400。
本篇论文中,研究者通过一种基于核的渐进式蒸馏方法构建了性能更好的加法神经网络。研究者表示,这项研究使得 ANN 性能超越了同结构的 CNN,从而在功耗更少的情况下实现更佳性能。这项研究还将有益于智能手机和物联网等的应用。
11月25日,论文一作、诺亚方舟实验室研究员许奕星将为大家详细解读此前沿研究。
原标题:《突破AI和机器理解的界限,牛津CS博士143页毕业论文学习重建和分割3D物体》
| 留言与评论(共有 0 条评论) |
