2013 Bossie评选:最佳开源大数据工具
2013 Bossie评选:最佳开源大数据工具,【IT168 评论】MapReduce的出现是为了突破数据库的局限。Giraph、Hama以及Impala等工具的出现则是为了突破MapReduce的局限。虽然上述方案的运行都需要以Hadoop为基础,但图形、文档、列式以及其它NoSQL数据库也是大数据当中不可或缺的组成部分。

哪款大数据工具能够满足您的需求?这个问题在如今解决方案数量迅速增长的背景之下,确实不容易回答。
当人们说起“大数据”或者“数据科学”时,他们指的往往是Hadoop项目。总体而言,Hadoop借用了MapReduce的框架,但该项目同时包含大量与数据存储及处理密切相关的重要工具。与MapReduce 2.0相似,全新YARN框架的出现标志着Hadoop迈出了发展道路上的关键步伐。大家可以期待着这一轮大数据浪潮很快出现在各位的业务环境当中。
目前还没有任何一家重量级新兴企业依靠Apache项目的支持,但Hadoop在这方面的人气则更高一些。分析人士预计,Hadoop将最终构建起年市值高达数百亿美元的巨大市场。大家千万别因为预算紧张而错过了这一波发展良机。
说起大数据处理,大家最先想到的肯定是Hadoop;但这并不代表传统数据库就无法胜任这项工作。事实上,多数情况下我们仍然需要从传统数据库中提取分析所需的数据,而这正是Apache Sqoop的长项。
Sqoop能够有效提高传统数据库系统与Hadoop之间的数据转换效率,这是因为它采用了并发连接、可定制数据类型映射以及元数据传播等一系列技术。大家可以将数据(例如纯新数据)导入至HDFS、Hive以及HBase当中,也能够将分析结果返回到传统数据库端。Sqoop还可以管理数据连接器带来的内存复杂性以及存在匹配失误的数据格式。
Talend的虚拟映射工具允许用户创建数据流并在无需涉及Pig的前提下加以测试。此外,项目进度安排与工作优化工具也进一步增强的工具包的功能阵容。
着手对大量数据进行整理分析的第一步,是将数据从多种来源处汇聚到Hadoop当中,而后再由Hadoop转移至其它平台。Talend Open Studio帮助大家在处理迁移流程时随心所欲,完全不必为担任复杂性而担忧。
Apache Giraph是一套图形处理系统,专为高扩展性及高可用性需求所打造。作为谷歌Pregel的开源替代方案,Giraph已经被Facebook公司用于分析用户社交图谱及其彼此关联。这套系统采用了来自Pregel的高效整体同步并行处理模式,从而避免了MapReduce在处理图形内容时存在的固有问题。好消息是:Giraph计算进程可在大家的现有Hadoop基础设施中作为Hadoop任务运行。只要同时运行其它一些同类工具,大家就相当于获得了分布式图形处理能力。推荐阅读:一致性检验,
与Giraph类似,Apache Hama同样将整体同步并行处理机制引入Hadoop生态系统当中,而且以Hadoop分布式文件系统作为运行基础。不过与专注于图形处理任务的Giraph不同,Hama是一套更具通行特性的框架,旨在执行大量模型与图像计算任务。它将Hadoop的良好兼容性与更为灵活的编程模式结合起来,为数据密集型科学应用提供出色的运行基础。
Cloudera Impala在实时SQL查询中的意义,可以等同于MapReduce在批量处理领域的重要作用。Impala引擎位于Hadoop集群的每一个数据节点当中,从而灵活地侦听查询请求。经过对查询的分析之后,它会通过优化生成一套执行规划,并在集群中的计算节点之间负责并行处理的协调工作。通过上述努力,Impala为用户在Haoop环境下带来更低的SQL查询延迟,并以接近实时的状态对大数据加以理解。
由于Impala也能直接使用大家的原生Hadoop基础设施(例如HDFS、HBase以及Hive元数据),多方配合将构成一整统一平台,用户可以在不涉及连接器复杂性、ETL或者昂贵数据仓库等机制的前提下实现全面数据分析。此外,Impala可以从任何ODBC/JDBC源处轻松获取,所以能够成为Pentaho等商务智能工具包中的理想组件。
作为VMware将虚拟化带入大数据处理领域的重要项目,Serengeti允许大家将Hadoop集群以动态方式运行在共享式服务器基础设施当中。该项目利用Apache Hadoop虚拟化扩展由VMware开发并贡献从而使Hadoop成功步入虚拟化环境。
在Serengeti的帮助下,我们可以在几分钟之内完成Hadoop集群环境部署,且不必涉及节点布局、HA状态或者作业调度等令人头痛的配置选项。进一步讲,通过在每台主机内的多套虚拟机系统中部署Hadoop,Serengeti能够将数据及计算功能加以划分,并在维护本地数据存储的同时改进计算规模。
Apache Drill的设计灵感源自谷歌Dremel系统,旨在为大规模数据集带来极低的交互分析延迟。Drill支持多种数据来源,包括HBase、Cassandra、MongoDB以及传统关系数据库。Hadoop虽然能为我们带来可观的数据吞吐能力,但分析其中的内容则要花费数分钟甚至数小时时间。在Drill的帮助下,大家将拥有理想的响应速度,从而实现交互式操作;这样一来,快速分析并获取有价值结论将变得轻松而愉快。
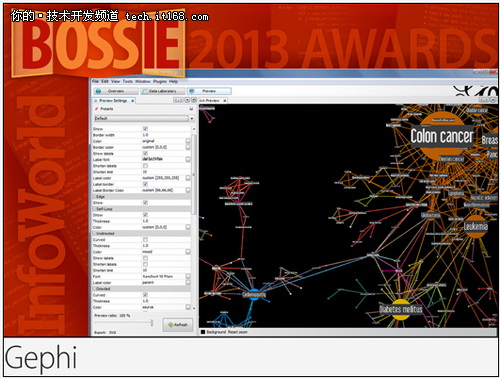
图形理论已经全面延伸到应用程序的各个领域。我们可以利用链式分析调查相关贸易商与员工,从而揪出可疑的交易活动。一旦明晰系统内关键性连接点的状况,我们就能以直观方式审视复杂的IT环境。在多位专家、企业联合组织的开发活动中,Gephi作为一款可视性发现工具,能够支持多种图形类型以及高达百万级别的网络节点规模。大家可以从维基、论坛以及各类教学网站上找到丰富的指导性资料,活跃的技术社区也为我们带来层出不穷的插件选项总而言之,大家在使用Gephi的过程中很可能无需从零做起。
作为一款具备敏捷性且速度极为出众的图形数据库,Neo4j能够以多种方式为用户提供帮助,包括社交应用、推荐引擎、欺诈活动检测、资源验证以及数据中心网络管理等等。Neo4j目前在性能提升(查询结果流处理速度)及集群化/HA支持表现方面仍然处于稳步发展当中。

在众多NoSQL数据库当中,最具人气的也许要数MongDB。它采用二元形式JSON文档实现数据存储,从而支持多种多样的文档形式、帮助开发人员获得远超过传统关系数据库的自由发挥空间后者强制要求我们在众多列表之间使用严格的平面开发模式。除此之外,MongoDB还提供开发人员需要从关系数据库中获得的全部功能。
2013年对于MongoDB发展史来说相当重要,今年我们迎来了两款新版本外加一系列新功能,其中包括文本搜索以及地理空间支持。新版本在性能改进方面也表现出色,例如采用并发式索引机制以及速度更快的JavaScript引擎(V8)。
与其它NoSQL数据库类似且与大部分关系数据库不同,Couchbase Server并不要求用户在插入数据之前首先创建什么架构。Couchbase Server的特性之一在于其内存缓存库。这项功能允许开发人员以无缝化方式由内存缓存环境向其它体系过渡,数据复制效果与而用性都令人满意,而且不会给应用程序造成停机。其2.0版本还增加了文档数据库功能。2.1版本在此基础上纳入跨数据中心复制与更为强大的存储性能。
SciDB是一套分布式数据库系统,利用并行处理对数据流进行实时分析。该系统的全部关注重点都放在大量科学数据集的支持效果上。它回避了关系数据库中常见的行、列模式,转而使用更适合有序数据集例如时间序列及位置数据的原生数列结构。与关系数据库或者MaoReduce不同,SciDB提供一套统一解决方案,能够在不涉及Hadoop多层基础设施与数据信息内容的前提下实现跨集群扩展。
上一篇:sci论文接收
| 留言与评论(共有 0 条评论) |

